It’s a Grind
Authenticated databases use tree structures like tries, binary search trees, and BTrees to support fast key lookup and generate a verifiable state (known as ‘merkleizing’). These structures work best when the keys are spread out evenly (uniformly distributed), and performance can suffer otherwise.
In adversarial environments such as those faced by permissionless blockchains, key uniformity is unfortunately not guaranteed. If you’ve been in crypto for any amount of time, your wallet’s activity history almost certainly contains at least one transaction involving an address you might believe you’ve interacted with in the past, but that actually differs in the bytes omitted in an abbreviated rendering.
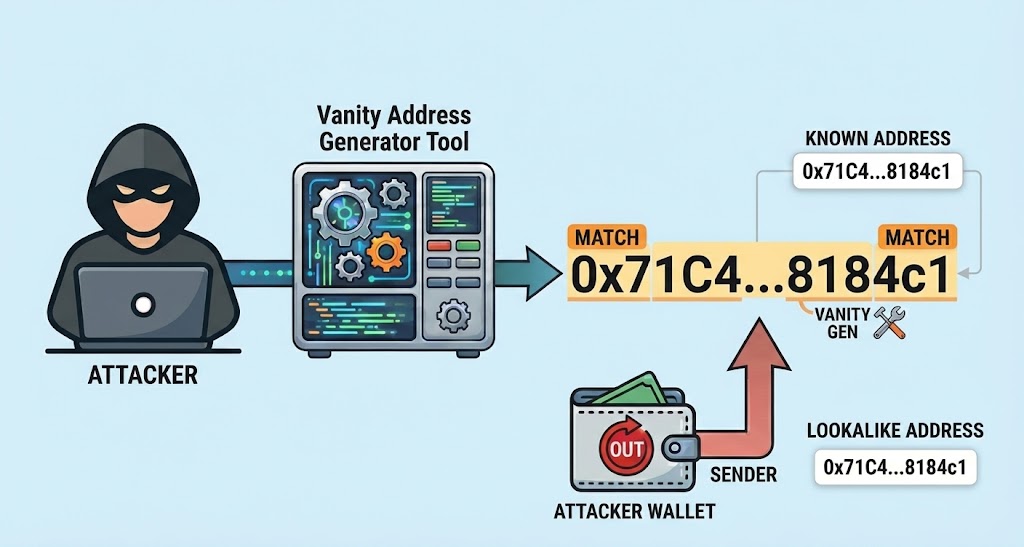
This is the classic address poisoning attack (Figure 1), where the attacker profits from the chance you might copy and paste the address when sending funds to, say, what you think is your exchange’s deposit address.
Poisoned addresses are produced through a computationally expensive procedure called grinding. But grinding isn’t limited to account addresses – an attacker can grind keys that satisfy many kinds of properties given the incentive and access to enough compute power.
Consider the trie structure, a type of search tree where a lookup requires traversing exactly k nodes from root to leaf, where k is the number of chosen key segments (e.g. characters, bytes, nibbles). No amount of key grinding will affect search depth in a trie! But the downside is that search depth is unconditionally poor. A typical key size in a blockchain state database is 32 bytes. Even with an unusually large key segment size of 1 byte (1 nibble is more common), we unconditionally traverse 32 nodes per lookup. Traversing 32 nodes per lookup may not seem like much, but if the structure’s nodes are scattered randomly across secondary storage, the result can be impractically slow.
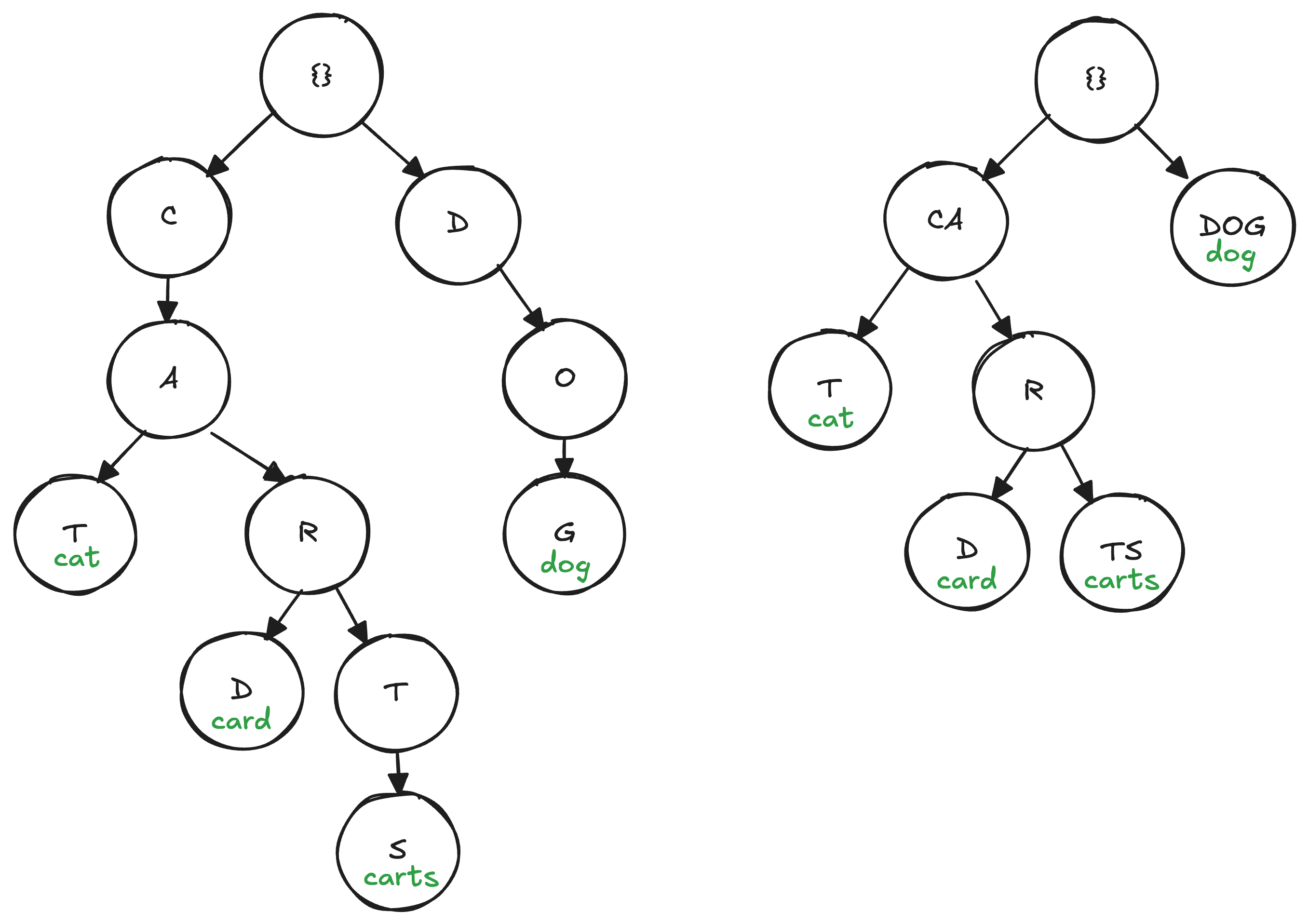
Many applications build on compressed versions of the trie such as the Patricia trie (aka radix tree) to reduce the average number of node traversals per lookup. The Patricia trie stores “extension nodes” that collapse a lengthy path into a single node if it terminates in only one descendant (fig 2). This optimization reduces the number of levels that must be traversed from exactly k to ~log_2(n), where n is the number of elements stored within it – at least under the assumption that keys are uniformly distributed. But as we pointed out earlier, there’s no such uniformity guarantee in the wild west of permissionless blockchains. An attacker could, for example, grind out keys that introduce child nodes all along a previously compressed path, reverting its compression and pushing the average case number of traversals towards the worst case (see Nurgle for a detailed analysis).
Another structure susceptible to grinding attacks is the hashtable. With knowledge of the hash function, an attacker can grind out many keys that all hash to the same bucket to increase the CPU required to fetch keys within it – a classic denial of service vector for many internet services over the years. As a result, modern hashtable implementations will (unless otherwise configured) randomly seed the hash function at startup, preventing an attacker from knowing whether any two keys might collide.
So, how do you deal with grinding attacks? Commonware’s
authenticated databases, like qmdb::any, use a Merkle
Mountain Range (MMR) over database operations for the canonical
structure. A Merkle mountain range is a tree structure with the
property that its maximum (not average) leaf depth is
log2(n) where n is the number of operations. Grind all you want;
your node’s depth won’t be affected (it’s independent of the
key’s content)!
But an MMR alone doesn’t allow for efficient key lookups, so QMDB couples the canonical MMR with a memory-efficient index that maps keys to their values on disk. By decoupling fast key lookup from merkleization, the exact structure of the index need not be canonical, allowing flexibility in its instantiation.
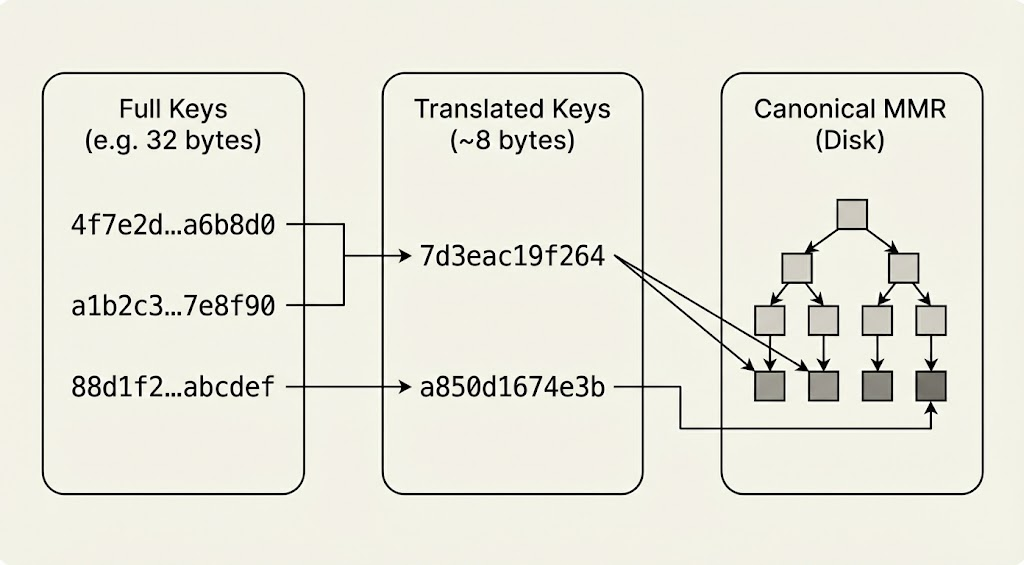
In QMDB, the index stores only a shortened (aka “translated”) representation of each key to reduce memory (fig. 3). Even if raw keys are the result of a cryptographic hash, if the key translation function is known, the index would be susceptible to grinding attacks that generate collisions among translated keys and degrade performance. Much as a good hashtable implementation will randomize its hash function, the Commonware index can be instantiated with a translator that applies a randomly-seeded hash per instance. Even in the unlikely event that an adversary learns the seed of one validator, it would differ from that of all others, providing the entire network strong immunity against DoS attacks from state key grinding.
TL;DR don’t canonicalize structures that can be manipulated by user input, or your database’s performance will be at the mercy of a grinder’s GPU.