Phone a Friend
Two advanced encryption schemes have gained traction to protect the privacy of pending transactions:
Identity-Based Encryption: Ciphertexts can be encrypted to arbitrary “strings” such that a signature on the string acts as the key to decrypt the ciphertext. If the signing key is secret shared amongst the validator set, they can sign the block height as a “timestamp” which enables encryption to a specific time in the future. More generally, you can sign arbitrary events, enabling conditional decryption of ciphertexts on chain. Concretely, this can be instantiated with BLS signatures as shown in BF01 or even with Silent Setup as shown in GKPW24.
Thus, each validator only broadcasts a constant amount of information to sign a message – but the signature can then be used to decrypt an arbitrary number of ciphertexts. But building an application on-chain with this requires some care.
Consider a sealed-bid auction where users encrypt their bid to some time T in the future, when the auction ends. It’s now entirely possible that a user’s bid is not included on chain before T and therefore never included as part of the auction, but after time T their bid can be decrypted. While you can mitigate this by ensuring users have sufficient time to have their bids included, this is not always reasonable in time sensitive applications such as trading.
Batched Threshold Encryption: This brings us to batched threshold encryption which allows the validator set to specify the exact set of ciphertexts that should be decrypted. At the same time, ensuring the communication from validators is independent of the number of ciphertexts in the batch. Since the primitive was introduced in CGPP24, there’s been a long line of work pushing the primitive closer to practicality.
Latest constructions of BTE [BNRT26, Pol26, ADG+26] have reduced the ciphertext size to |\mathbb{G}_1| + |\mathsf{msg}| – just 16 bytes longer than threshold ElGamal (over ed25519) when instantiated with BLS12-381. Decryption is the fastest amongst all known schemes but nevertheless still requires O(B\log{B}) group operations and O(B) pairings.
Both IBE and BTE still require a few pairings to decrypt a ciphertext which places a lower bound of \approx 1 ms per transaction. Processing 100K transactions would still require 100s in single-core CPU time!
How do we scale?
To avoid designing bespoke solutions for every primitive, we will use the observation from GHKKP25 that many pairing-based advanced encryption schemes including IBE/Timelock Encryption [BF01, DHMW23, GMR23], Batch Threshold Encryption/IBE [CGPP24, CGPW25, AFP25], Silent Threshold Encryption [GKPW24], ABE [SW05], Distributed Broadcast Encryption [KMW23] and more can be viewed as witness encryptions for relations of the form:
\underbrace{ \begin{bmatrix} A_{1,1} & \cdots & A_{1,n} \\ A_{2,1} & \cdots & A_{2,n} \\ \vdots & \ddots & \vdots \\ A_{m,1} & \cdots & A_{m,n} \end{bmatrix} }_{\text{public statement}} \circ \underbrace{ \begin{bmatrix} w_1 \\ w_2 \\ \vdots \\ w_n \end{bmatrix} }_{\text{secret witness}} = \underbrace{ \begin{bmatrix} b_1 \\ b_2 \\ \vdots \\ b_m \end{bmatrix} }_{\text{public statement}}
Here \circ denotes a pairing (and its natural extension to matrix multiplication), the entries of A and w are from compatible source groups, and the entries of b lie in \mathbb{G}_T. Given randomness \alpha=(\alpha_1,\ldots,\alpha_m), encryption of a message M has the form \mathsf{Enc}(M, (A,b)):
\mathsf{ct}_0 := M + \sum_{i=1}^{m}\alpha_i b_i, \qquad \mathsf{ct}_j := \sum_{i=1}^{m}\alpha_i A_{i,j} \quad\text{for }j\in[n].
Given a valid witness w, decryption recovers the message as \mathsf{Dec}(\mathsf{ct}, w):
M \gets \mathsf{ct}_0 - \sum_{j=1}^{n}\mathsf{ct}_j \circ w_j.
Phone a Friend: Instead of every single validator carrying out the work of decryption, a well-provisioned helper can do the work once and broadcast hints to the network which will be used to quickly verify the result. More formally, there exists a method:
\mathsf{HintDec}((\mathsf{ct}^1,\ldots,\mathsf{ct}^B), \mathsf{hint}) \to (m^1,\dots,m^B)
which takes as input a batch of B ciphertexts \mathsf{ct}^1, \ldots, \mathsf{ct}^B and a hint \mathsf{hint}, and outputs the messages m^1, \ldots, m^B or \bot. Of course \mathsf{HintDec} is non-trivial only if it offers a speedup over the naive decryption algorithm. For security, we will require that it is computationally infeasible to produce a \mathsf{hint} such that:
\mathsf{HintDec}((\mathsf{ct}^1,\ldots,\mathsf{ct}^B), \mathsf{hint}) \neq (\mathsf{Dec}(\mathsf{ct}^1, w^1), \ldots, \mathsf{Dec}(\mathsf{ct}^B, w^B))
even for adversarially chosen ciphertexts (\mathsf{ct}^1,\ldots,\mathsf{ct}^B), where the probability is taken over the randomness of the adversary. Thus we only rely on the helper for liveness and a malicious helper cannot violate safety by equivocating hints.
A First Attempt
In some pairing based proof systems, it’s possible to reduce the verification of N pairing product equations to MSMs of size N and a single pairing product equation. In fact, we used this idea in our previous blog post on batch verification of Pari proofs.
A natural approach is to have the helper send the recovered message together with the corresponding witness as the hint. The verifier can then check the decryption equation is satisfied for all of the ciphertexts by sampling random coefficients and applying the test from FGHP09. This reduces many checks to a single pairing-product equation. However, the number of pairings only reduces when there is a common input across the different pairing terms: \prod_{i=1}^B e(g_i, h)^{r_i} = e\left(\sum_{i=1}^B r_i g_i,\; h\right).
So if all ciphertexts use the same witness, the verifier can fold pairings across the B ciphertexts with an MSM. Fortunately, this is the case for Timelock encryption as the witness is a signature on the block height. But if each ciphertext has its own unrelated witness, which is the case in most other applications of pairing based WE schemes, the verifier will have to evaluate a large number of pairings.
Our Approach
We start from a simple observation:
A perfectly correct encryption scheme is also a perfectly binding commitment scheme
If a helper provides us the message and randomness used to create the ciphertext, we can avoid the decryption equation check entirely. Instead, we can check that the ciphertext is a valid encryption of the claimed message under the claimed randomness. In the linear WE notation above, this means checking:
\mathsf{ct}_j \stackrel{?}{=} \sum_{i=1}^{m}\alpha_i A_{i,j} \quad\text{for every }j\in[n], \qquad \mathsf{ct}_0 - M \stackrel{?}{=} \sum_{i=1}^{m}\alpha_i b_i.
These checks use MSMs in the source groups and target group, but no pairings. They also batch naturally via FGHP09: sample random coefficients r_1,\ldots,r_B\gets\mathbb{F} and check the random linear combination of the claimed openings:
\sum_{k=1}^{B} r_k\mathsf{ct}^k_j \stackrel{?}{=} \sum_{k=1}^{B}\sum_{i=1}^{m} r_k\alpha^k_i A^k_{i,j} \quad\text{for every }j\in[n],
and
\sum_{k=1}^{B} r_k(\mathsf{ct}^k_0-M^k) \stackrel{?}{=} \sum_{k=1}^{B}\sum_{i=1}^{m} r_k\alpha^k_i b^k_i.
The missing piece is actually recovering the randomness from the ciphertext. A simple approach is to just encrypt the randomness in a separate ciphertext, but this comes at a 2\times penalty in ciphertext size and encryption/decryption time.
Randomness Recovery
Our approach uses the Fujisaki-Okamoto transform for randomness recovery. It’s important to note that this does not provide CCA security in the threshold decryption setting as the committee would need to securely carry out certain checks during decryption that require interaction. So constructions such as batched threshold encryption still require additional mechanisms such as Simulation-Extractable NIZKs for CCA security.
Let \mathcal{K} be the message space of the underlying WE scheme, and
H_R:\mathcal{K}\times\{0,1\}^{\ell_m}\to\{0,1\}^{\ell_\rho}, \qquad H_M:\mathcal{K}\to\{0,1\}^{\ell_m},
be random oracles, and let G:\{0,1\}^{\ell_\rho}\to\mathbb{F}^m be a PRG. To encrypt a message M \in \{0,1\}^{\ell_m}, sample K\gets\mathcal{K}, derive
\rho := H_R(K,M), \qquad \alpha := G(\rho),
and output:
\mathsf{ct}' := \left(\mathsf{Enc}((A,b), K; \alpha),\; H_M(K)\oplus M\right).
This gives two possible choices for the hint:
Bandwidth-optimized: the helper sends the short PRG seed \rho^k (16 bytes) for each ciphertext. Parse the k-th transformed ciphertext as \mathsf{ct}^{\prime k}=((\mathsf{ct}^k_0,\mathsf{ct}^k_1,\ldots,\mathsf{ct}^k_n), c^k) where c^k=H_M(K^k)\oplus M^k. For each k\in[B], the verifier computes
\alpha^k := G(\rho^k), \qquad K^k := \mathsf{ct}^k_0-\sum_{i=1}^{m}\alpha^k_i b^k_i, \qquad M^k := c^k\oplus H_M(K^k),
checks \rho^k=H_R(K^k,M^k), and then batch-verifies \mathsf{ct}^k_j=\sum_{i=1}^{m}\alpha^k_i A^k_{i,j} for every j\in[n].
Verification-optimized: the helper sends K^k directly (576 bytes) for each ciphertext. For each k\in[B], the verifier computes
M^k := c^k\oplus H_M(K^k), \qquad \rho^k := H_R(K^k,M^k), \qquad \alpha^k := G(\rho^k).
It then batch-verifies:
\mathsf{ct}^k_j = \sum_{i=1}^{m}\alpha^k_i A^k_{i,j} \quad\text{for every }j\in[n], \qquad \mathsf{ct}^k_0-K^k = \sum_{i=1}^{m}\alpha^k_i b^k_i.
This uses larger hints, but avoids the per-ciphertext target-group work needed to recover K^k from a seed.
Scaling Batched Threshold Encryption
Coming to the specific case of batched threshold encryption there are two remaining hurdles:
- While some constructions of BTE such as CGPW25 and AFP25 have been presented as witness encryption schemes, it is not obvious how we can view constructions such as Simple BTE as a witness encryption scheme.
- We have completely ignored the issue of malformed ciphertexts. Suppose a user submits a ciphertext that fails the FO decryption check such that the helper cannot recover randomness. Observe that the helper cannot just output \bot, because a malicious helper could suppress honest ciphertexts by falsely claiming they are malformed. Instead, the helper needs to prove the ciphertext is malformed. One can of course attach a SNARK but this is quite expensive and we would like to do better.
Simple BTE as a Witness Encryption Scheme
We recall the simple BTE construction from our previous blog post.
Encrypt: An ElGamal-style ciphertext:
\mathsf{ct} := \left([k]_1,\; m + [k\tau^{B+1}]_T\right)
Partial Decrypt: To decrypt a batch (\mathsf{ct}_i)_{i\in[B]}, each validator j holding shares (\sigma^i_j)_{i\in[B]} of (\tau^i)_{i\in[B]} broadcasts:
\mathsf{pd}_j := \sum_{i\in[B]} \sigma_j^i\cdot \mathsf{ct}_{i,1}
Any t partial decryptions are combined via Lagrange interpolation to reconstruct:
\mathsf{pd} = \left[\sum_{i\in[B]} k_i\tau^i\right]_1
At first glance, one might view each ciphertext as a witness encryption for the relation
[1]_1\circ w=[\tau^{B+1}]_T.
Clearly the only witness that can satisfy this relation is w = [\tau^{B+1}]_2 but the decryptor never learns it. In fact, they never should as it allows them to decrypt all ciphertexts (even outside the batch). Instead, consider the following relation R_j:
\begin{bmatrix} [1]_1 & 0 & \cdots & 0 & [\tau]_1 \\ 0 & [1]_1 & \cdots & 0 & [\tau^2]_1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & \cdots & [1]_1 & [\tau^B]_1 \end{bmatrix} \circ \begin{bmatrix} w_1\\ w_2\\ \vdots\\ w_B\\ w_{B+1} \end{bmatrix} = \begin{bmatrix} 0\\ \vdots\\ [\tau^{B+1}]_T\\ \vdots\\ 0 \end{bmatrix},
where the non-zero entry on the right-hand side is in the j-th row. If we run the WE encryption algorithm for R_j with randomness (k_1,\ldots,k_B), the resulting ciphertext has the form:
\left( [k_1]_1,\ldots,[k_B]_1,\; \left[\sum_{i=1}^{B}k_i\tau^i\right]_1,\; [k_j\tau^{B+1}]_T+m \right).
As it turns out, if we want to encrypt different messages \{m_j\}_{j \in [B]} under relations \{\mathcal{R}_j\}_{j \in [B]}, respectively, we can securely share the randomness (k_1,\dots,k_B) between the ciphertexts. This can also be viewed as a witness PRF, where ([k_1]_1,\ldots,[k_B]_1, \left[\sum_{i=1}^{B}k_i\tau^i\right]_1) is the secret key and (0,\ldots,[\tau^{B+1}]_T,\ldots,0) is the statement at which the PRF is evaluated.
This leads to a compression in the ciphertext size from B(B + 1)\times\mathbb{G}_1 + B\times \mathbb{G}_T group elements to (B + 1)\times\mathbb{G}_1 + B\times \mathbb{G}_T group elements.
\mathsf{ct} =\left( [k_1]_1,\ldots,[k_B]_1,\; \left[\sum_{i=1}^{B}k_i\tau^i\right]_1,\; [k_1\tau^{B+1}]_T+m_1,\ldots,[k_B\tau^{B+1}]_T+m_B \right).
This is precisely the batch of ciphertexts together with the partial decryption in the simple-BTE scheme! Thus the users and the committee produce the ciphertext \mathsf{ct} in a distributed manner.
Decrypt: To decrypt the i-th ciphertext, we use \{h_{\ell+B+1-i}\}_{\ell\in[0,B]\setminus\{i\}} as the witness which is readily available in the public parameters. m_i = \mathsf{ct}_{i,2} - \mathsf{pd}\circ h_{B+1-i} + \sum_{\substack{\ell\in[B]\\\ell\ne i}} \mathsf{ct}_{\ell,1}\circ h_{\ell+B+1-i}
Malformed Ciphertexts
The construction above assumes the helper can recover the randomness for all ciphertexts. However, a malicious user can always submit a malformed ciphertext that fails the decryption checks. In this case, the helper cannot simply output \bot, because a malicious helper could suppress a valid ciphertext by falsely claiming it is malformed.
One strategy is to have the helper provide the witness for the underlying relation as part of the hint. This allows the verifier to run the decryption locally and confirm that the ciphertext is malformed. Indeed, this would work for [CGPW25, AFP25] since the witness is O(1) group elements. But as we saw above, the witness for the Simple BTE relation is actually O(B) group elements and decryption requires O(B) pairings. Naively using the above strategy would quickly destroy the benefit of helper-aided verification. In our paper, we show how to use Inner Pairing Product Proofs to certify the malformed ciphertexts more efficiently.
Evaluation
We benchmarked the batch verification of decryption for the simple BTE scheme on an M5 MacBook Pro in single-threaded mode. Our implementation using arkworks can be found here.
| B | Helper | Naive | Bandwidth-opt. | Verification-opt. |
|---|---|---|---|---|
| 32 | 121.61 ms | 89.61 ms (1.4 \times) | 11.53 ms (10.5 \times) | 7.274 ms (16.7 \times) |
| 128 | 596.13 ms | 415.27 ms (1.4 \times) | 45.48 ms (13.1 \times) | 14.93 ms (39.9 \times) |
| 512 | 2.84 s | 1.927 s (1.5 \times) | 179.46 ms (15.8 \times) | 34.45 ms (82.4 \times) |
| 2048 | 12.78 s | 8.751 s (1.5 \times) | 726.68 ms (17.6 \times) | 112.01 ms (114.1 \times) |
| 16384 | 120.76 s | 82.584 s (1.5 \times) | 5.867 s (20.6 \times) | 611.20 ms (197.6 \times) |
| 32768 | 262.54 s | 174.005 s (1.5 \times) | 12.006 s (21.9 \times) | 1.136 s (231.1 \times) |
| 65536 | 556.09 s | 366.852 s (1.5 \times) | 23.937 s (23.2 \times) | 1.988 s (279.7 \times) |
Helper refers to the time it takes to carry out decryption. Producing hints has negligible overhead. For the batch verification, we benchmarked three different strategies:
- Naive: This is the “first attempt” described above where the helper sends the recovered message together with the corresponding witness as the hint, and the verifier checks the decryption equation for each ciphertext.
- Bandwidth-optimized: This is the strategy described above where the helper sends the short PRG seed \rho^k for each ciphertext but this comes at the cost of \mathbb{G}_T exponentiations for each ciphertext.
- Verification-optimized: This is the strategy described above where the helper sends the recovered K^k values directly and only uses MSMs/Hashes for verification.
While these benchmarks were run in single-threaded mode on an M5 MacBook Pro, we expect them to scale well with parallelization.
Applications
We now outline two applications of helper-aided decryption.
Reducing Operating Costs of Encrypted Mempools
Consider a globally distributed network of validators running a chain with encrypted mempools. Each transaction is assumed to be ~400 bytes (typical trades fit in ~300 bytes and we add ~100 bytes for ciphertext overhead). At 65K TPS, the proposer needs to push about 26 MB of data to every participant in the network, every second. To aid in scaling, we can use sub-batching where the committee decrypts multiple batches but of a smaller size in each slot. Each batch can then be processed in parallel, potentially across different machines. Concretely, let’s assume we use four sub-batches each with a batch size of 16384 and the partial decryption increases from 48 bytes to 192 bytes.
Local Decryption: If all validators carried out the decryption locally, they would need to speed up decryption by over \approx 500 \times. In theory, this can be achieved by running four large instances that come with 128 vCPUs each (say) and cost \approx 4 \times \$6.5 per hour, but this is much more expensive than the \$2-\$3 per hour it normally costs to rent compute as a validator.
With helper aided decryption:
- In the Verification-optimized version, the helper needs to distribute an additional 38 MB of data to every participant in the network, every second. However, this comes with the benefit of being able to batch verify the decryption of ciphertexts in under 2s (single threaded) instead of spending 556s decrypting them. When bandwidth is abundant and we have room to double the throughput, this is the preferred option.
- In the Bandwidth-optimized version, the helper needs to distribute just 1 MB of data to every participant in the network, every second. The validators spend about 24 s (single threaded) verifying the decryption but this can of course be parallelized. This allows us to retain the benefits of batched verification (23 \times speedup) with a modest (~4%) increase in bandwidth usage.
In the figure below, we provide a visual representation of the three different decryption strategies. Pricing is estimated by assuming perfect parallelization of single threaded performance and calculating the number of threads required to attain 65K TPS. For local decryption we use 4 \times c8id.32x large instances (128 vCPUs each), for verification optimized hints we use r6id.large (2 vCPUs), and for bandwidth optimized hints we use z1d.6xlarge (24 vCPUs). Reducing costs through the use of specialized hardware such as GPUs/FPGAs is an interesting avenue for future work.
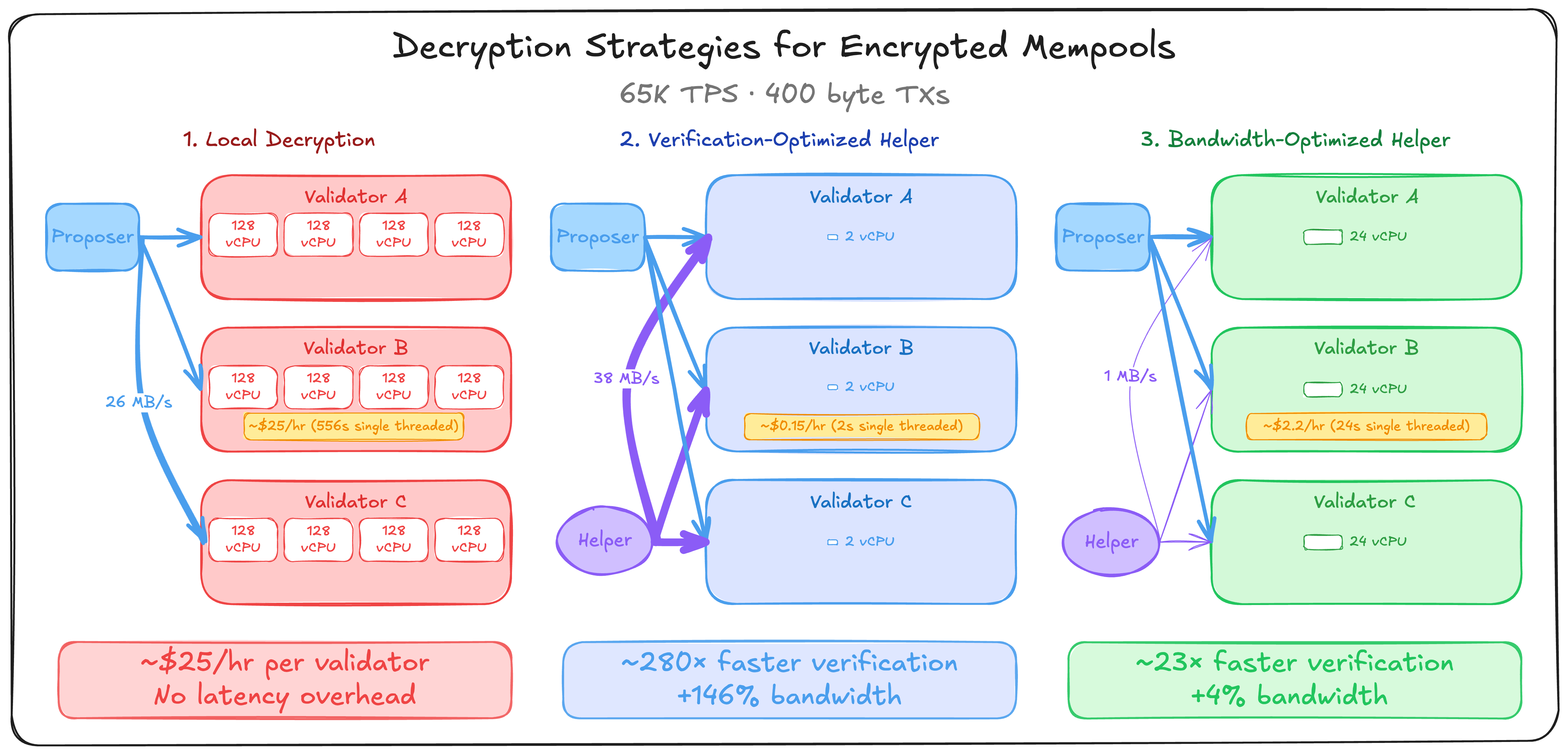
In both helper aided architectures, even though the helper spends a lot more resources to carry out decryption, the marginal cost to support additional validators is sending ~1 MB of hints. Thus, we are able to support the same level of decentralization with minimal overhead.
A knee-jerk criticism is that validators must wait to receive hints from the helper which increases latency. We dig deeper and address these concerns.
We envision a system where there are dedicated fee paying accounts which can only be used to pay the fees for encrypted transactions. Additionally, we delay the state root update by a small number of slots, say 10 blocks. Because the balances of fee paying accounts are never encrypted, they can be updated immediately by validators even without hints. Transactions that can pay base fee can be sorted and proposed based on priority fees.

While it’s true that validators will incur additional latency before they see the latest state of the chain, note that it does not materially affect their ability to propose and vote on blocks. Thus, they have no motivation to decrypt faster (as the data being sequenced is encrypted). Specialized parties such as RPC providers / Searchers / Market Makers are incentivized to decrypt transactions quickly in order to gain an edge and can then act as helper parties assisting the network. The buffer for state root updates also makes helper failures easier to absorb: the network can fall back to another helper or to local decryption, spreading the recovery process across several slots rather than forcing all validators to catch up in a single block.
Blinded Sequencer
Most rollups today use a single sequencer who is responsible for building and proposing blocks but they have a lot of influence over the chain as they can censor/reorder transactions. Currently, users (at best) get a promise that their transactions will not be censored/frontrun but there are no formal guarantees.
Instead, consider a dedicated sequencer where transactions are encrypted to some committee who will release partial decryption shares only after the sequencer commits. This provides the performance benefits of a single sequencer but with a cryptographic guarantee of transaction privacy until inclusion. Concerns around censorship through metadata such as fee payer accounts/IP address leakage can be mitigated via anonymous tokens or routing transactions through an RPC provider that acts as the fee payer.
Furthermore, the sequencer itself can act as the helper party and broadcast hints to the network. This colocation allows the sequencer to begin a large chunk (~90%) of the decryption work that we refer to as “pre-decryption” immediately after it has built the block. It does not have to wait for decryption shares to be released and allows decryption work to be pipelined with block dissemination.