Honey, I Shrunk the Proofs!
Grab your magnifying glass: QMDB’s Merkle proofs are getting smaller.
QMDB’s original MMR-based proof scheme made updates efficient and grinding-resistant, but proof sizes were tied to historical updates U rather than active values V. By combining an active-region-aware bagging policy, pyramid bagging, with the Merkle Mountain Belt (MMB), our new scheme makes active-value proofs small and predictable: within two digests of a balanced binary Merkle tree over those values (without sacrificing the append-only structure that drew us to Merkle Mountain Ranges in the first place).
When restricted to k-ary hashing, the Merkle structure that minimizes leaf depth (and hence proof size) in both the worst and (uniform) average case is a balanced binary Merkle tree (BMT). More exotic cryptography such as vector commitments and SNARKs can deliver even smaller proofs than Merkle structures (example), but with a number of non-trivial trade-offs and complexities we won’t dive into here.
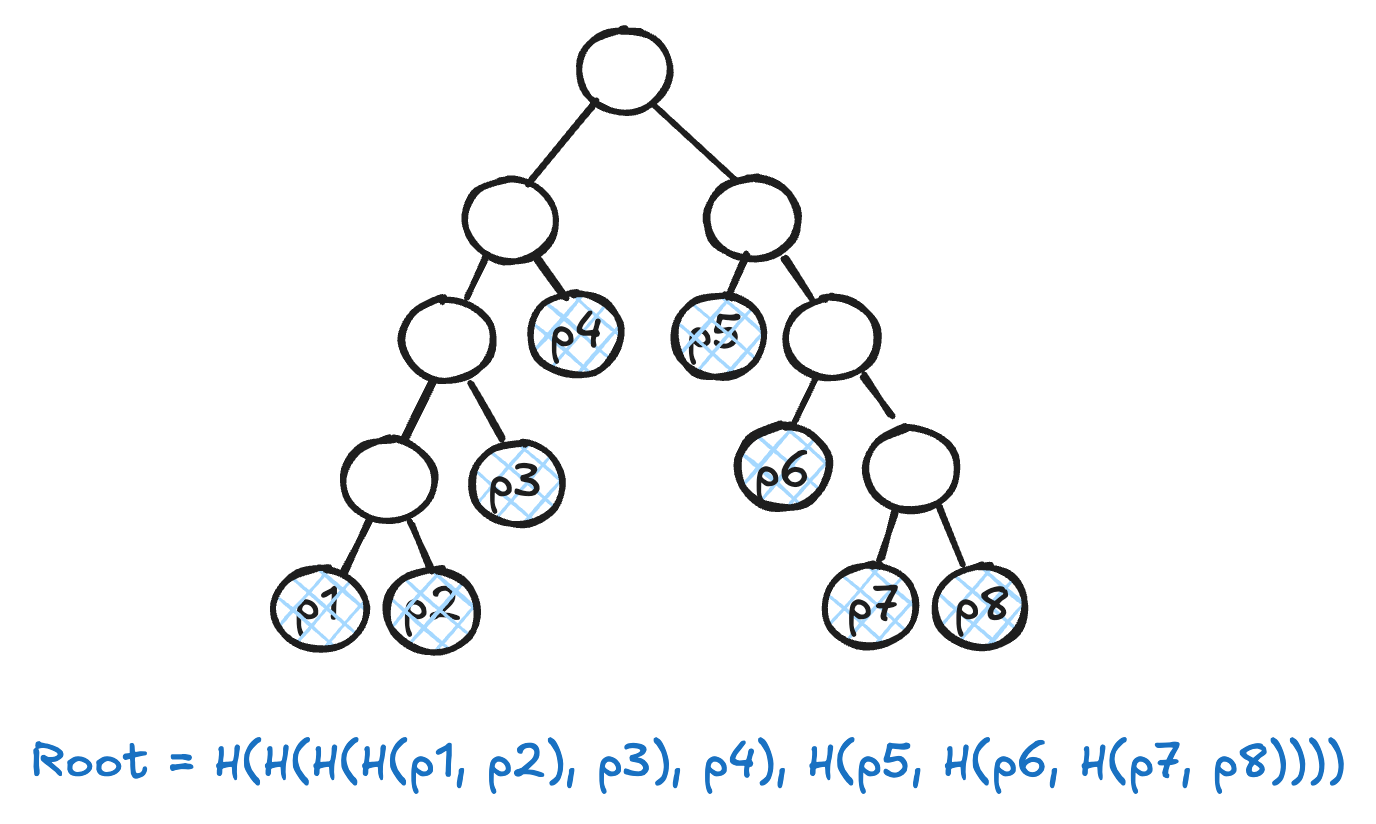
As we’ve described in earlier articles [1], [2], Commonware’s QMDB [3] implementation relies on a Merkle Mountain Range [4] (MMR) applied to a log of database updates. We adopted an MMR because of its incredible efficiency in handling updates and resistance to grinding [5], but at what cost does this come with respect to proof efficiency? Instead of having depth logarithmic in the number of values V (stored in its leaves) like a BMT, the MMR has depth logarithmic in the number of updates U. The number of updates is strictly greater (sometimes much greater) than the number of active values, since most updates are for existing keys, and many keys eventually get deleted. The MMR may introduce additional inefficiencies over a BMT depending on how peaks are bagged, which we detail shortly. Still, it’s conceivable that a typical MMR proof may not be much larger than those from a BMT, unlike those from Merkle structures with high node fan-out like Ethereum’s (hexary) state trie.
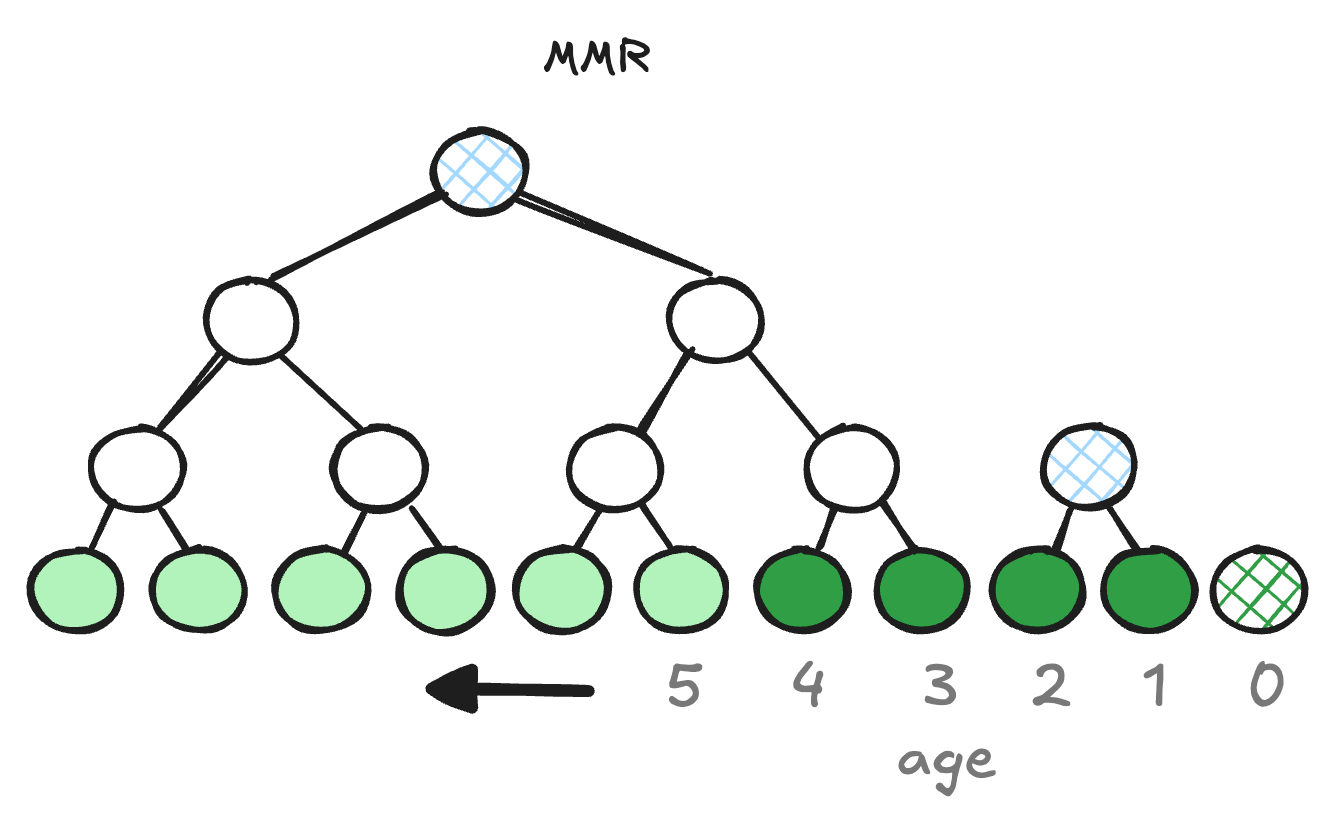
Precisely quantifying MMR proof inefficiency over a BMT requires establishing a bit more context. First, while the worst-case proof size from an MMR over updates is clearly larger than the worst-case proof size of a BMT over database values, it’s important to also consider the average-case proof size, as well as proof size variance (all three are important). Second, QMDB involves continuously moving active values to the tip of the log, and for the most part we’re interested primarily (if not exclusively) in proving over active values. Define the age of an element in the log as its distance from the tip (the most recent update therefore has an age of 0). If there are V active values in the database, the incremental compaction policy in our implementation guarantees no active value has a corresponding update with age greater than 2V. This means proofs in our system are almost always over leaves that are far to the right in the MMR, regardless of how long the update log has grown. Third, proof size corresponds to the depth of the proven element in the Merkle structure. Since MMRs consist of perfect trees of strictly decreasing height, the depth of an element is, on average, smaller the further to the right it resides in the structure (Fig. 1).
Unfortunately, even taking in all the above, the worst-case proof behavior of an MMR over updates remains quite a bit worse than a tree over only active values, and it occurs when the number of elements (leaves) is an exact power of 2. All mountains collapse into a single tree of depth \log_2(U), where U is the number of updates (recall that U \gg V). The inclusion proof for any value, whether or not it is active, therefore requires at least \log_2(U) digests.
The average case behavior tells a better story, but still not a great one. Analyzing average case behavior requires we look beyond the degenerate case of 2^k elements and consider how we deal with more than one mountain. When there’s more than one mountain in the structure, computing the root (aka commitment) of the structure requires combining (or bagging) the peaks into a single digest. Just as we pairwise-hash leaves to derive ancestor digests in the MMR, we pairwise-hash peaks in order to derive the structure’s root. And the exact strategy we use to perform these |\text{peaks}| - 1 pairwise hashes can have a profound impact on proof size.
Consider the example in Fig. 2, which shows what’s called a “forward” (oldest to youngest) bagging strategy. We can analogously define the backward bagging strategy which folds the peaks from youngest to oldest. Many more schemes are possible! Another simple strategy is min-depth, which bags peaks according to a binary Merkle tree over them.
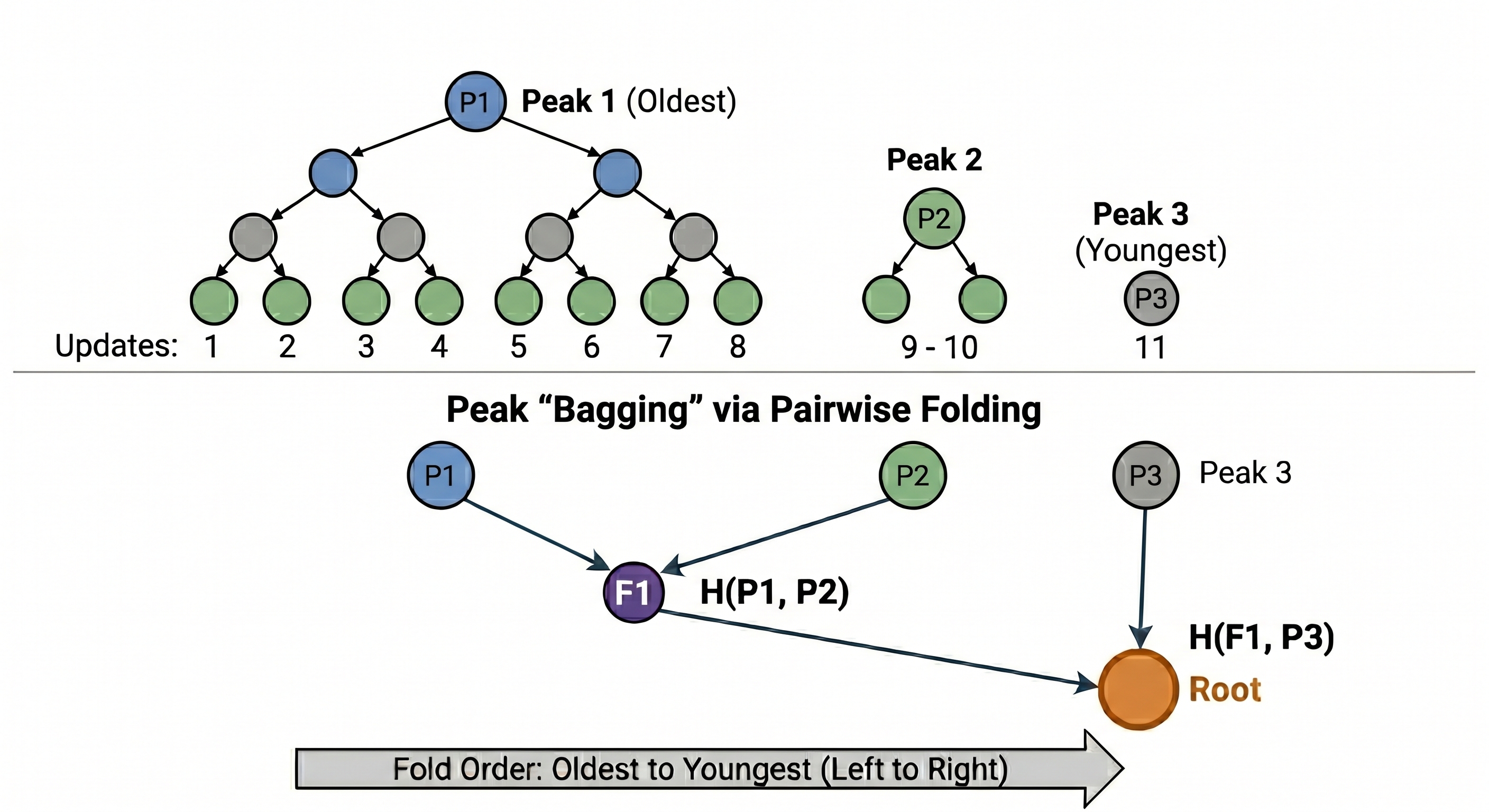
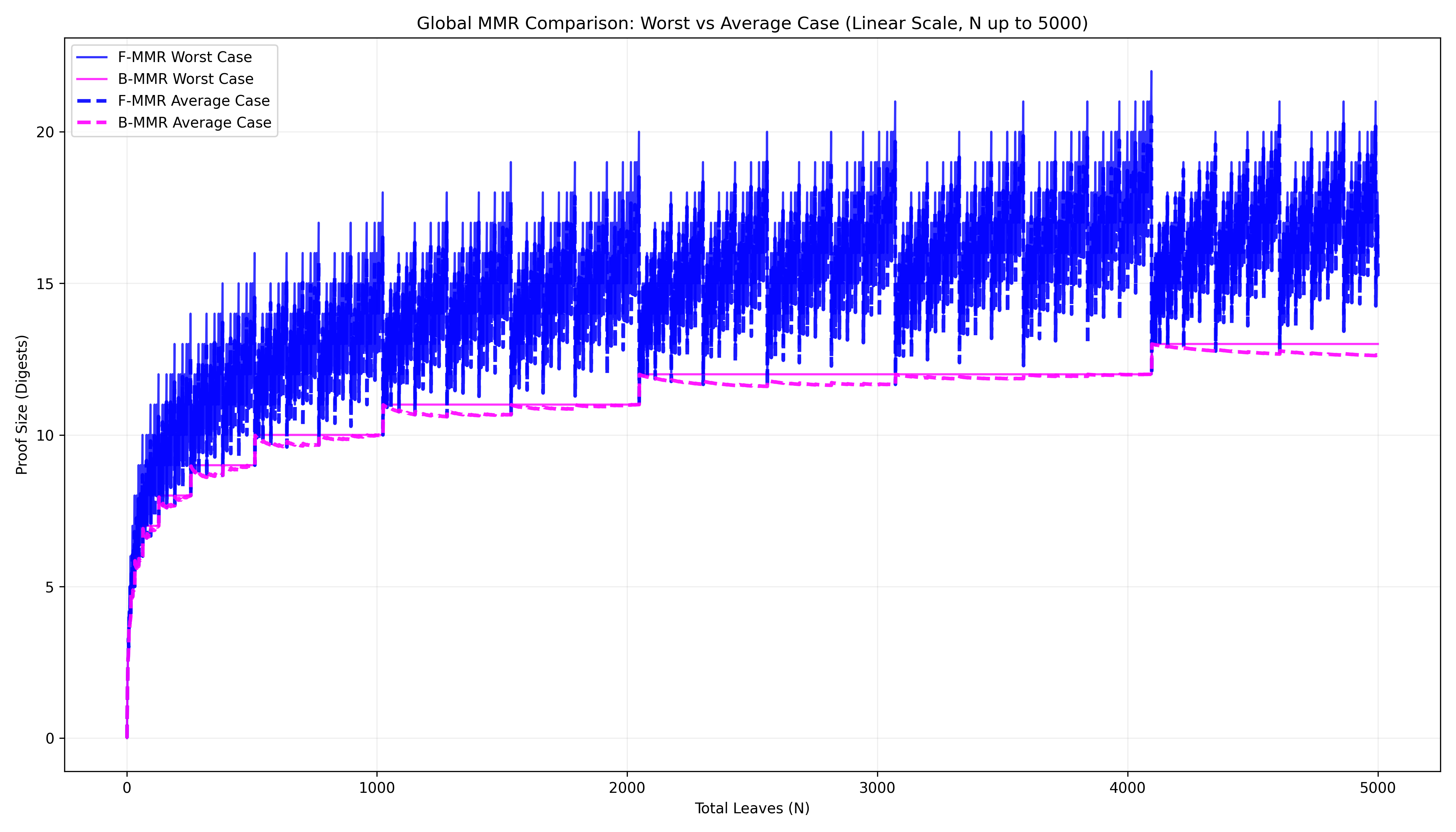
If we’re looking to minimize either worst-case or average-case proof size over all elements of an MMR, the backward-bagging strategy is provably optimal (by the strictly decreasing peak height property)! In comparison, forward bagging doubles the worst-case proof size, and increases the average case considerably (Fig. 3).
If it seems the case is closed when it comes to how to bag peaks, recall that in our particular application, we’re far more interested in proof sizes over the younger elements since that’s where our active state resides. Focusing only on these elements paints a more complex picture (Fig. 4). Average-case proof size of the two bagging strategies when looking only at the last ~1M elements begins to favor the forward bagging strategy at a large enough database size.
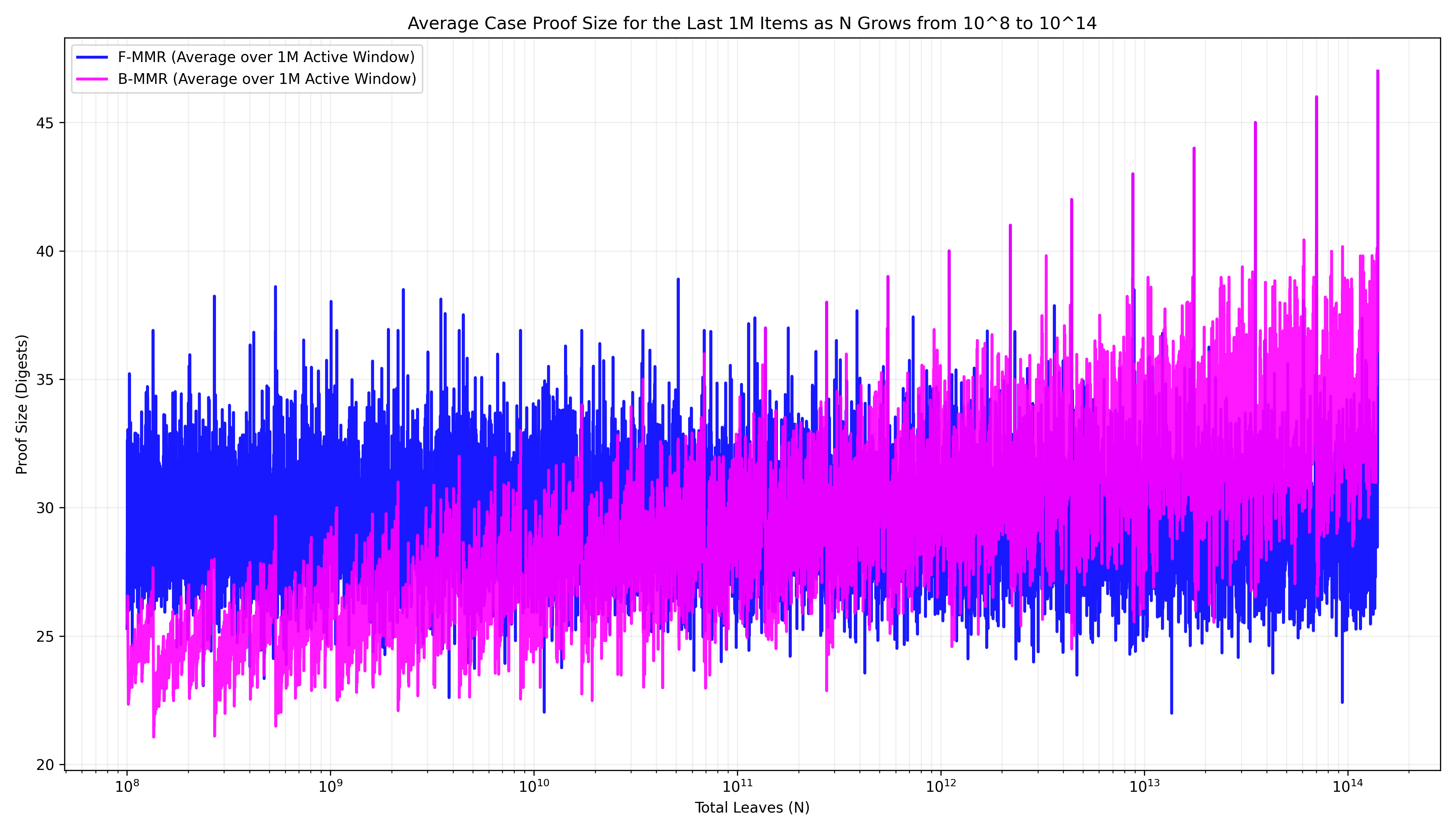
If you’re now thinking “forward bagging FTW!”, you’re only half right. While forward bagging elegantly collapses the entire ancient history into a single digest, it introduces a new inefficiency: elements in the largest active peaks are forced to provide every smaller active peak to their right individually. On the flip side, backward bagging perfectly optimizes the active peaks, but “pollutes” the proof with ancient history. Backward bagging the MMR from Fig. 1, for example, results in the digest of peak P1 appearing in every proof, even those for active elements in the disjoint trees to its right. Seems a bit unnecessary?
This insight suggests a new, active strategy that is aware of the inactivity boundary. While our simple graphs assume the inactivity boundary is always at age 1M, in practice it will vary over time. But at any given point where we need to generate a root or proof, the QMDB inactivity floor is derivable from the commit operation at the tip of the log. Instead of a naive forward or backward-only strategy, what if we were to forward-bag all peaks “covering” nodes entirely within the inactive range, and backward-bag the remaining? We call this policy pyramid bagging because it can be visualized as a tree with only two branches that looks a bit like a (possibly lopsided) 2D pyramid (Fig. 5). Proofs for elements in the active range contain at most one peak from the inactive range, and still benefit from the average-case improvements provided by backward bagging. Average proof size indeed plummets when pyramid bagging is used (Fig. 6).
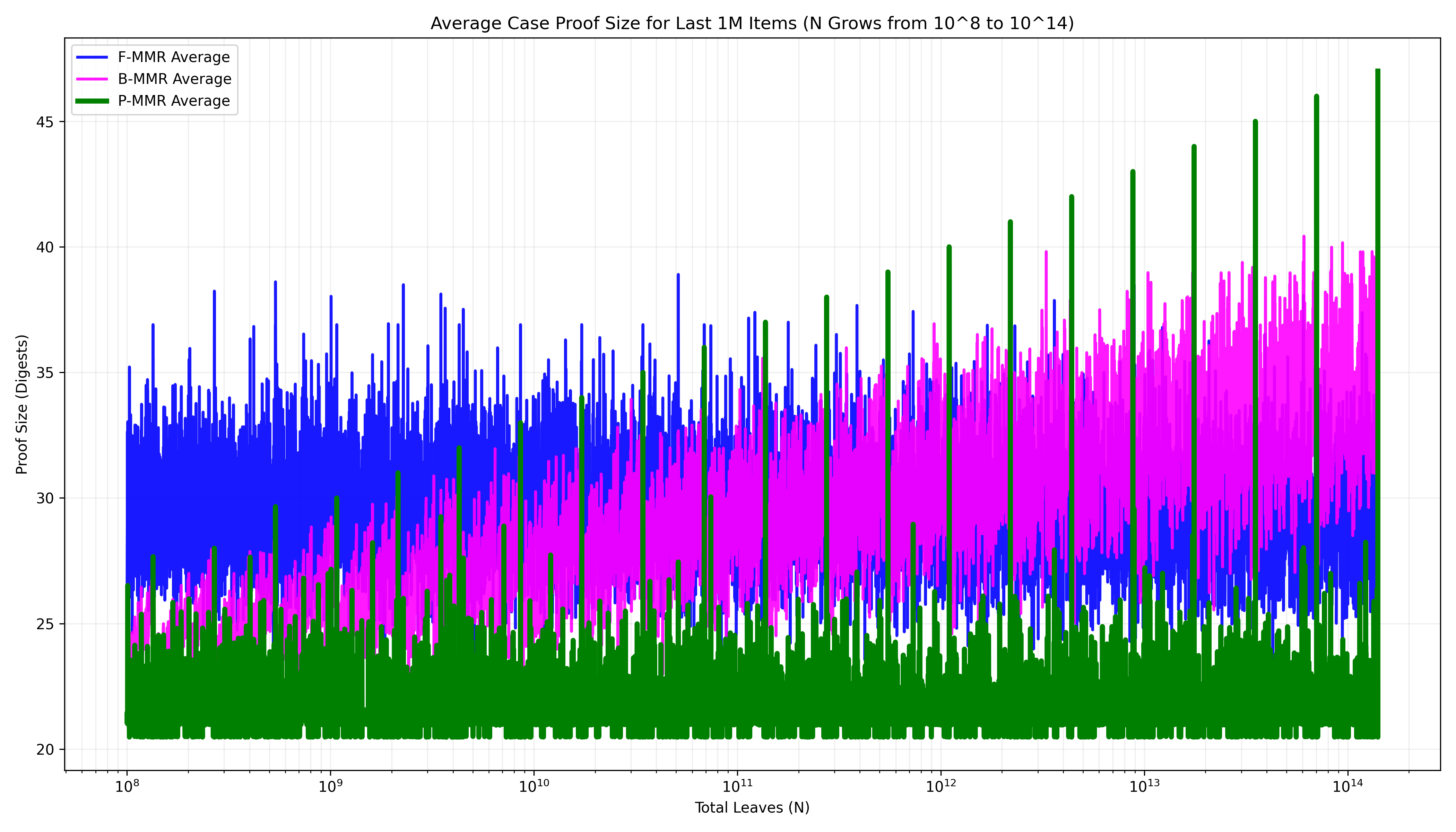
While pyramid bagging delivers a huge win in proof size on average, it still suffers from the exact same worst-case behavior as the other bagging schemes, even over recent elements. This can be seen from the spikes in Fig. 6 (appearing at N a power of 2), where all three schemes produce the exact same worst and average-case proof size of \log_2(N) despite all our efforts. It’s also frustrating, and potentially problematic for low-bandwidth clients, that the proof sizes vary so considerably even for small changes in the database size.
We address these final concerns through a recent innovation known as the Merkle Mountain Belt [6]. A Merkle Mountain Belt (MMB) can be thought of as an MMR with a different update rule that adds ancestor nodes at a slightly slower pace, along with a special bagging policy. In an MMR, we may have to add up to \log(U) ancestor nodes with each new update. With an MMB, we always add at most one ancestor per update.
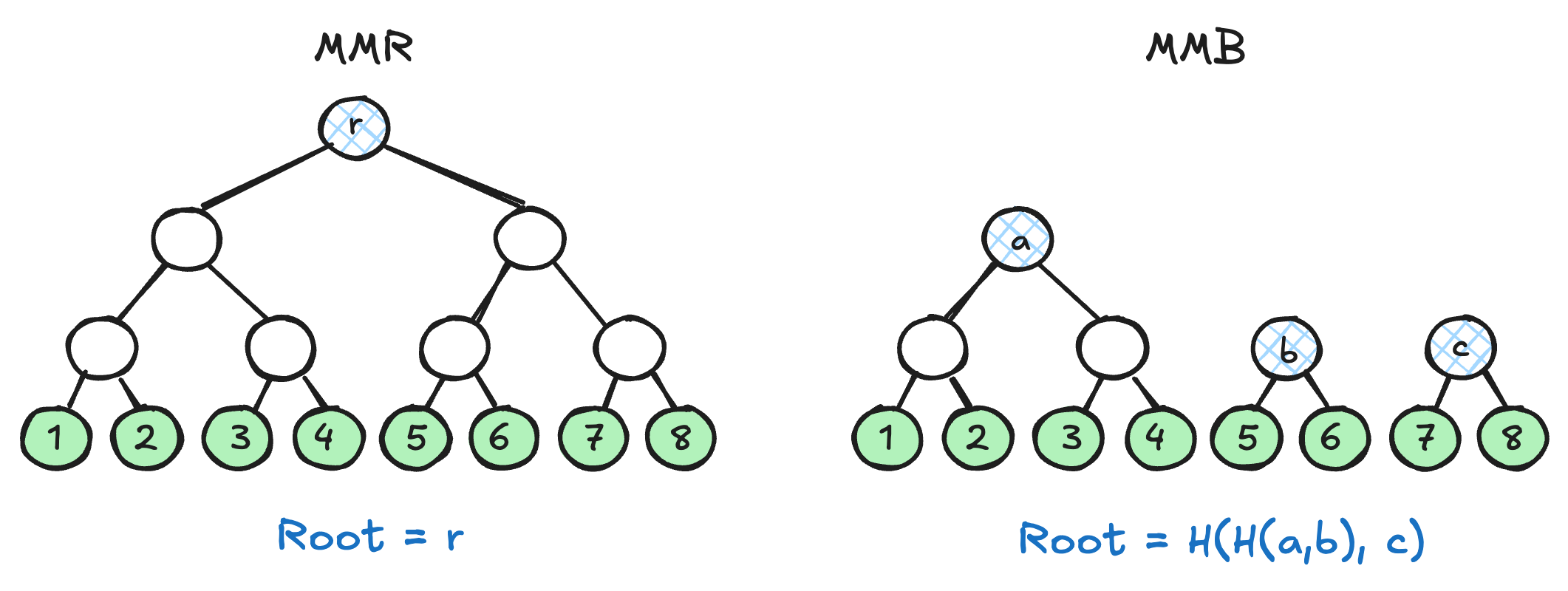
The MMB has mountains of decreasing height, but that decrease is not strict: it may have up to two consecutive mountains at the same height (Fig. 7). In the worst case, then, the MMB may have twice the number of peaks that must be bagged to derive the root compared to an MMR. This might seem a step in the wrong direction, and in fact proofs of old elements within an MMB are larger than those from an MMR over the exact same data (though only by a small constant: both retain an O(\log(U)) bound overall). But the MMB has an additional remarkable property: the depth of an element in the structure is bounded by a logarithmic function of its age. It therefore doesn’t just provide small proofs of recent elements on average, it guarantees it.
This remarkable MMB property bounding proof size by age, however, is not independent of the bagging policy. One that is compatible is forward bagging (F-MMB). A more complex compatible policy proposed in the MMB paper provides other interesting properties such as O(1) root update time with each tree update. But this latter property is of little interest in our domain, where roots are computed only after large batches of updates (such as after processing an entire block of transactions).
Unfortunately, a backward bagging policy when applied to an MMB-style update rule is not compatible with the O(\log(\text{age})) property. But it does result in something quite interesting: the resulting Merkle structure is isomorphic to a balanced binary Merkle tree over all elements! In other words, each element’s proof has the same size (within 1 digest), completely eliminating variance in proof size.
Combined with pyramid bagging, the MMB update rule gives us the best of all worlds: proof size is bounded by \log_2 of the active range, average-case proof size over the active range is minimized (Fig. 8), and variance is eliminated. Applied to QMDB then, a proof over an active element contains at most \log_2(2V) = \log_2(V) + 1 digests. Put another way, the maximum penalty in proof size of a P-MMB over the optimal structure (a BMT over the active values alone) is a mere 2 digests. Analytically, the worst-case proof size of a P-MMB is 50% smaller than the F-MMB over the active range, and average-case proof size is 33% smaller.
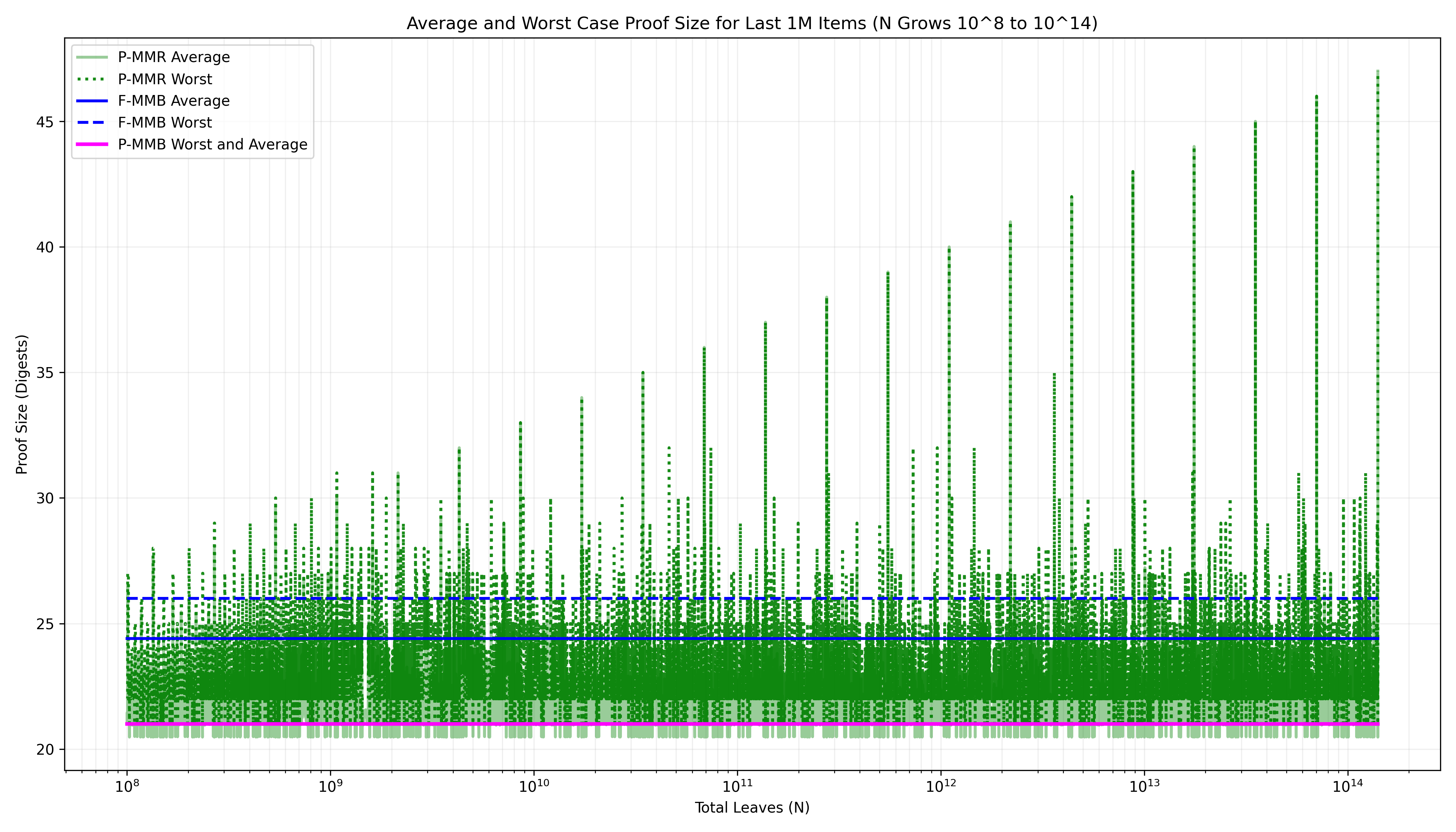
All QMDB implementations in the Commonware Library perform pyramid bagging and can be instantiated with either an MMR or MMB. If you’ve been curious about the performance of append-only authenticated stores but were scared off by \log(U) proof scaling, less than ideal average-case proof size, or high proof size variance, it’s time to give them another look.